









Fine-tuning large-scale models has traditionally been a time-consuming and resource-intensive process. However, with LoRA and QLoRA, adapting LLaMA 3 becomes significantly more efficient. These techniques introduce a lightweight approach to parameter updates, reducing computational overhead while preserving model performance. This guide explores how LoRA and QLoRA optimize the fine-tuning process, making advanced AI models more accessible and scalable.
The trend of fine-tuning large language models (LLMs)
Fine-tuning large language models (LLMs) has evolved significantly, making customization more efficient and accessible. Traditional fine-tuning methods often require extensive computational power, making them impractical for many applications. However, advancements such as LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) have introduced a parameter-efficient fine-tuning (PEFT) approach, reducing the need for full model retraining.
The trend of fine-tuning LLMs using advancements such as LoRA or QLoRA
These techniques enable selective model adaptation, fine-tuning pre-trained LLMs for specific tasks without requiring massive GPU clusters. By leveraging LoRA and QLoRA, organizations can streamline AI deployment, optimize resource usage, and accelerate model iteration cycles, making fine-tuning more practical than ever before.
Currently, some of the most widely used LLMs and vision-language models (vLMs) include:
LLaMA 3 (Meta) – Optimized for efficiency and open-weight accessibility.
GPT-4 (OpenAI) – A powerful general-purpose model with strong reasoning capabilities.
Claude 3 (Anthropic) – Focused on safety and alignment.
Mistral/Mixtral – A high-performance open-weight alternative with mixture-of-experts architecture.
DeepSeek-VL – A vision-language model optimized for multi-modal understanding.
Gemini 1.5 (Google DeepMind) – A multi-modal AI model with advanced capabilities.
This blog focuses on fine-tuning LLaMA 3 using LoRA and QLoRA, which were chosen for their efficiency, open-weight availability, and strong performance across various NLP tasks. Unlike proprietary models such as GPT-4, which operate as closed systems, LLaMA 3 provides greater flexibility for customization. This allows developers to fine-tune the model for specific applications while maintaining an optimal balance between performance and resource efficiency, making it a practical choice for a wide range of AI-driven solutions
What is LLaMA 3?
Before diving into fine-tuning methods, let's briefly touch on what makes LLaMA 3 stand out. LLaMA is a series of open-weight models released by Meta AI (formerly Facebook AI). LLaMA 3 builds upon its predecessors with better performance on a variety of benchmarks, offering state-of-the-art language understanding, generation, and translation capabilities. The model has been trained on vast amounts of data, which makes it versatile for everything from chatbots to content generation, summarization, and even creative writing.
But, like any large language model, LLaMA 3 isn't always optimized for specific tasks out of the box. That’s where fine-tuning comes into play.

LLaMA is a model developed by Meta
The fine-tuning challenge
Fine-tuning large language models like LLaMA 3 presents several challenges, particularly in terms of computational resources, cost, and data efficiency. Below are three key obstacles that arise when fine-tuning LLaMA 3:
High computational demand: LLaMA 3 consists of millions or even billions of parameters, requiring high-end GPUs with large memory capacities to process. The sheer size of the model makes training resource-intensive, often putting significant strain on hardware.
Expensive training process: Adjusting the model’s parameters for a specific task requires storing and updating massive datasets, leading to high computational costs. Without optimized fine-tuning techniques, the process becomes costly and inefficient, making it inaccessible to many developers.
Risk of overfitting on small datasets: Fine-tuning on limited datasets can cause the model to memorize rather than generalize, resulting in overfitting. This reduces its ability to perform well on real-world data, impacting accuracy and adaptability.
So, to overcome these limitations, LoRA and QLoRA offer a more efficient approach. These techniques enable fine-tuning with reduced memory consumption and computational overhead, making it feasible to adapt LLaMA 3 without excessive hardware demands.
Understanding LoRA and QLoRA
LoRA: Low-rank adaptation
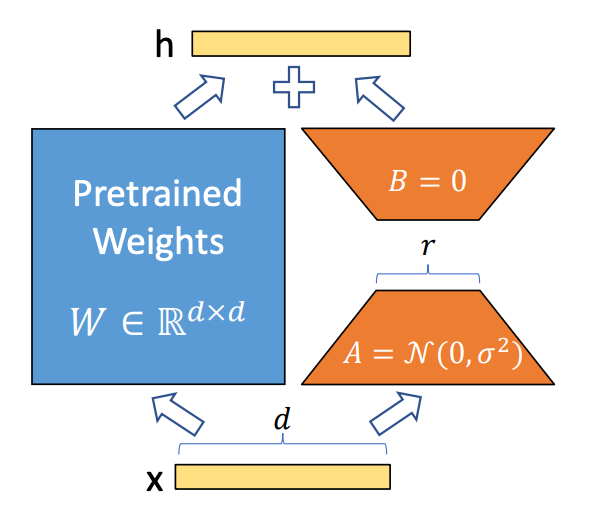
LoRA is built based on neural network architecture
The Neural Network contains multiple dense layers that perform matrix multiplication, and the weight matrices in these layers are typically full rank. Aghajanyan (2020) stated that pre-trained language models have an "intrinsic dimension" and can be represented in a lower dimension compared to the original model while still maintaining performance when fine-tuned. Based on this idea, the LoRA method was developed to decompose the weight change (ΔW) into a representation with a lower rank. This method does not require direct computation of (ΔW). Instead, LoRA learns the decomposition of (ΔW) directly during the training process. Specifically, for a pre-trained weight with a matrix W ∈ R (d x k), we assume the condition of learning the matrix decomposition representation: W + ΔW = W + BA, where B ∈ R(d x r), A ∈ R (r x k), and the rank r << min(d, k). During training, W will be frozen and its weights will not be updated, the matrix A is initialized with a Gaussian distribution, and the matrix B is initialized with zeros. From this, we obtain the following output:
From the formula above, we can see that the output is unaffected and the inference time after training with LoRA will not be impacted. Why does decomposing the matrix ΔW into two matrices, A and B, reduce the computation?
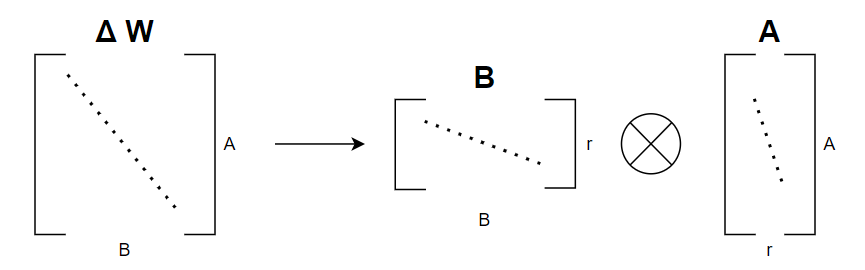
Looking at about figure, the number of elements that the matrix ΔW initially has is A x B, whereas after decomposing ΔW into two matrices A and B, the number of elements becomes: B x r + A x r. Since matrices A and B are often large, when you plug in the values into the decomposed matrix, it typically ends up being smaller than the original matrix. Currently, LoRA only supports decomposing the weights of the Linear layer and does not support other layers.
QLoRA: Quantized LoRA
Quantized LoRA is a combination of quantization and LoRA to help train large models more easily. QLoRA introduces three elements to help finetune the quantized model more effectively:
NF4 (Normal Float 4): A new dtype that uses only 4 bits but offers better precision compared to using the typical Int4 or Float4 dtype.
Double Quantization
Paged Optimizers: To avoid OOM errors, things that would cause the GPU to run out of memory (VRAM) are temporarily moved to the CPU (from VRAM to RAM). When the GPU needs it for computation, the temporary storage from the CPU is retrieved for processing.
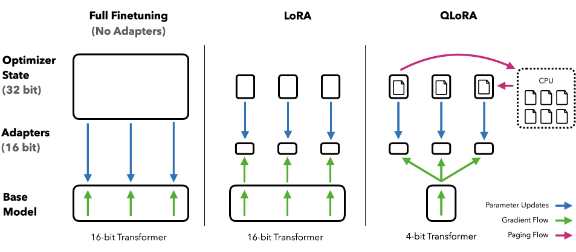
This is QLoRA
Similar to LoRA, QLoRA currently only supports the Linear layer, which consists of two components: the pre-trained part, which is frozen and does not update gradients, and the part that needs to be trained, which is LoRA. The weights of the pre-trained part are quantized to NF4. Since current GPUs do not support 4-bit precision, during computation, the pre-trained part is dequantized from NF4 to BF16, and then combined with the LoRA component in BF16 for calculation. After the computation, the pre-trained part is quantized back to NF4. This process allows QLoRA to fit the model into VRAM for training. However, it doesn't accelerate the model (since we need to dequantize to BF16 whenever a layer needs computation), meaning QLoRA's training time will be slower than LoRA.
LoRA is implemented in the Hugging Face Parameter Efficient Fine-Tuning (PEFT) library, offering ease of use and QLoRA can be leveraged by using bits and bytes and PEFT together. HuggingFace Transformer Reinforcement Learning (TRL) library offers a convenient trainer for supervised finetuning with seamless integration for LoRA. These three libraries will provide the necessary tools to finetune the chosen pre-trained model to generate coherent and convincing product descriptions once prompted with an instruction indicating the desired attributes.
Why use LoRA and QLoRA for LLaMA 3?
Fine-tuning LLaMA 3 requires significant computational resources, but LoRA and QLoRA offer a more efficient approach. These methods optimize performance while reducing hardware demands, making fine-tuning more accessible.
Resource efficiency: Both methods drastically reduce the computational overhead compared to full fine-tuning, making it feasible to adapt models like LLaMA 3 (70B parameters) on smaller hardware setups.
Cost-effectiveness: By limiting the number of trainable parameters, these techniques lower training costs while maintaining high performance.
Scalability: QLoRA’s quantization enables fine-tuning even larger models without requiring high-end GPUs.
Step-by-step guide to fine-tuning LLaMA 3 with LoRA and QLoRA
1. Setting up the environment
This blog will explore LLaMA Factory as a framework commonly used for training large language models.
Installation
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"2. Data preparation
Download dataset
This implementation utilizes the public BillSum dataset from Hugging Face, a dataset designed for summarizing U.S. legislative bills. More details can be found here https://huggingface.co/datasets/FiscalNote/billsum?row=0
Format dataset
Training data must follow LLaMA-Factory’s format. Example about formatted data:
{
"instruction": "Summary of the following paragraph",
"input": "SECTION 1. SHORT TITLE.\n\n This Act may be cited as the ``Merchant Marine of World War II \nCongressional Gold Medal Act''.\n\nSEC. 2. FINDINGS.\n\n The Congress finds the following:\n (1) 2015 marks the 70th anniversary of the Allied victory \n in World War II and the restoration of peacetime across the \n European and Pacific theaters.\n (3) Fleet Admiral Ernest J. King acknowledged the \n indispensability of the Merchant Marine to the victory in a \n 1945 letter stating that without their support, ``the Navy \n could not have accomplished its mission''.\n… Numismatic Items.--For purposes of section 5134 of title 31, \nUnited States Code, all medals struck under this Act shall be \nconsidered to be numismatic items.\n\n Passed the House of Representatives November 30, 2016.\n\n Attest:\n\n KAREN L. HAAS,\n\n Clerk.",
"output": ". Merchant Marine of World War II Congressional Gold Medal Act (Sec. 3) This bill requires the Speaker of the House of Representatives and the President pro tempore of the Senate to arrange for the award, on behalf of Congress, of a single gold medal to the U.S. Merchant Marine of World War II, in recognition of their dedicated and vital service during World War II. Following its award the medal shall be given to the American Merchant Marine Museum where it will be available for display and research."
},Formatted data is saved to data/summarization_data_train.json. Add a dataset description in data/dataset_info.json and specify dataset: dataset_name before training to use it. Example:
{
"summarization_data_train": {
"file_name": "summarization_data_train.json"
}
}For more details please refer https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README.md
3. Fine-tune
To assess the impact of different LoRA configurations, multiple fine-tuning experiments were conducted on LLaMA 3, adjusting LoRA hyperparameters to analyze their effect on model performance.
Hyperparameter combination #1: LoRA with r=8 and targeting all linear layers
The first combination of LoRA hyperparameters attempted is r=8 and targets all linear layers.
These choices result in 5,636,096 parameters being updated during the fine-tuning process (~5.6 million) from a total of ~1.5 billion parameters the model consists of. This is less than 4% of the model parameters.
Hyperparameter combination #2: LoRA with r=16 and targeting all linear layers
Surely, things can be improved here. It is worth exploring increasing the rank of low rank matrices learned during adaptation to 16, i.e. double the value of r to 16 and keep all else the same. This doubles the number of trainable parameters to 11,272,192 (~11.3 million).
Hyperparameter combination #3: LoRA with r=8 and targeting “q_proj”, “v_proj”
These choices result in 851,968 parameters being updated during the fine-tuning process (~0.85 million).
In every experiment, the batch size is set to 4.
LoRA rank | target modules | Number of parameters updated | BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | GPU-Memory |
8 | All linear layers | 5,636,096 | 14.44 | 33.65 | 17.56 | 22.51 | 16GB |
16 | All linear layers | 11,272,192 | 17.82 | 41.40 | 25.10 | 29.10 | 18GB |
8 | Attention blocks | 851,968 | 14.24 | 31.35 | 14.66 | 20.58 | 16GB |
Observations
The rank 16 configuration consistently outperforms the rank 8 configurations across all metrics, while it also trains more parameters and requires more GPU memory.
The attention blocks approach shows the most parameter efficiency, achieving reasonable performance while updating significantly fewer parameters and maintaining the same GPU memory usage (16GB) as the rank 8 linear layers approach.
There's a clear correlation between the number of parameters updated and GPU memory requirements, with the rank 16 configuration requiring more memory (18GB vs 16GB).
These experiments demonstrate how different LoRA configurations impact resource requirements and fine-tuning efficiency. Increasing the rank (r) significantly increases the number of trainable parameters but also demands more GPU memory. For teams with limited GPU resources, targeting specific layers like q_proj and v_proj can be an effective alternative to full linear layer adaptation.
Further tests can explore QLoRA, which applies quantization techniques to reduce memory usage while retaining model performance. This will be covered in the next section of our study.
In this blog, the lora rank is 8 and lora target is all linear layers
Create file config examples/train_lora/llama3_lora_sft.yaml:
### model
model_name_or_path: meta-llama/Llama-3.2-1B-Instruct
trust_remote_code: true
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all
### dataset
dataset: summarization_data_train
template: llama3
cutoff_len: 2048
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/llama3.2-1b-instruct/lora/sft
logging_steps: 2
save_steps: 50
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 4
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 1.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
## eval
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 50For more detail:
model_name_or_path: path to model’s hugging face repository. If you want to change to a different model for experimentation, replace it with the model’s ID on Hugging Face.
stage: model training phase: supervised fine-tuning (sft), pre-training (pt), reward modeling (rm), ppo-training (ppo), …
finetuning_type: lora training (lora) or full fine-tuning (full)
lora_rank: the intrinsic rank of the weight decomposition in LoRA
lora_target: Name(s) of modules to apply LoRA. Use commas to separate multiple modules. (all, q_proj, v_proj, …)
dataset: dataset name from data/dataset_info.json
template: family model, ex: llama3 (LLaMA3.1, LLaMA3.2, …), deepseek3 (DeepSeekV3, DeepSeekV2.5, DeepSeekR1 (Distill) …), …
Use the following command for fine-tuning:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yamlThe loss during the training process is shown in the image below.
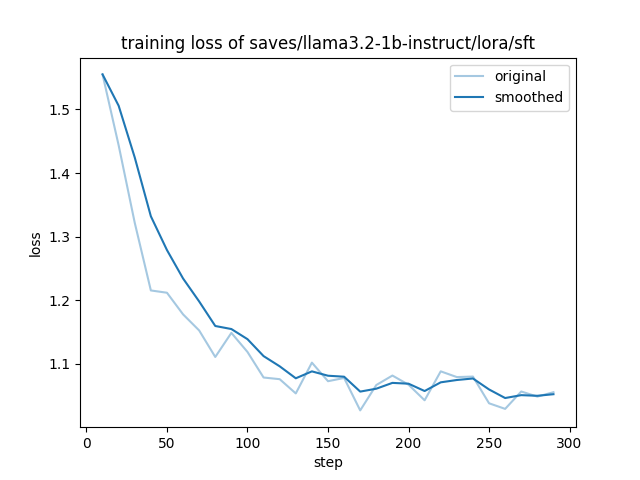
Fine-tuned model is saved in saves/llama3.2-1b-instruct/lora/sft
Merge LoRA
Create file config examples/merge_lora/llama3_lora_sft.yaml
### model
model_name_or_path: meta-llama/Llama-3.2-1B-Instruct
adapter_name_or_path: saves/llama3.2-1b-instruct/lora/sft
template: llama3
trust_remote_code: true
### export
export_dir: output/llama3
export_size: 5
export_device: cpu
export_legacy_format: falseadapter_name_or_path: folder contains LoRA checkpoint
Use the following command for merger LoRA
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yamlAll the code for this blog is at the Colab link.
4. Evaluating model performance
The fine-tuning experiments were conducted on a server with an NVIDIA GTX 3090 GPU to assess model performance under more accessible hardware constraints. The evaluation was based on the BLEU-4 and ROUGE metrics, which are commonly used for NLP tasks.
BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-L | LoRA rank | GPU Mem | |
Before fine-tuning | 11.92 | 26.17 | 8.67 | 15.19 | - | - |
LoRA fine-tuning | 19.64 | 44.20 | 27.67 | 31.40 | 8 | 16 GB |
QLoRA fine-tuning (4 bit) | 19.87 | 44.45 | 27.97 | 31.64 | 8 | 6 GB |
Observations
LoRA fine-tuning (r=8) significantly improved performance across all evaluation metrics compared to the pre-trained model.
QLoRA (4-bit quantization) achieved slightly better results than LoRA while using substantially less GPU memory (6GB vs. 16GB), making it a viable option for lower-end hardware setups.
The improvements in ROUGE-2 and BLEU-4 scores suggest that both fine-tuning approaches enhance the model's ability to generate coherent and relevant text.
Next steps
Exploring higher LoRA ranks: Increasing the LoRA rank (e.g., r=16) could lead to further improvements, though it would require more GPU resources.
Fine-tuning with QLoRA on larger datasets: Given its efficiency, applying QLoRA on more extensive datasets might yield even better generalization.
Multi-step fine-tuning: Combining LoRA and QLoRA sequentially to leverage both efficiency and high-rank adaptation.
Experimenting with different optimizers: Evaluating AdamW vs. Lion optimizer for better convergence and stability.
Further tests will focus on refining these techniques to maximize performance while maintaining efficiency.
Which to use to fine-tune LLMs?
Choosing between LoRA and QLoRA depends on your hardware resources and fine-tuning requirements.
Using LoRA if:
You have decent hardware, with at least 16GB of VRAM for optimal performance.
You want a simple and efficient fine-tuning method without added complexity.
You prefer full-precision fine-tuning, where memory constraints are not a concern.
You need faster training speeds and stable performance, avoiding the trade-offs of quantization.
Using QLoRA if:
You are working with limited GPU memory but need to fine-tune large models (30B+ parameters) on a single consumer GPU.
You want to maximize memory efficiency using 4-bit quantization while maintaining fine-tuning flexibility.
You need to train massive models on constrained hardware, such as research setups or budget-limited environments.
You are optimizing for low-resource deployment, making models more efficient for real-world applications.
Conclusion
LoRA is a powerful fine-tuning technique that can yield great results if used with the right configuration. Choosing the correct value of rank and the layers of the neural network architecture to target during adaptation could decide the quality of the output from the fine-tuned model. QLoRA results in further memory savings while preserving the adaptation quality. Even when the fine-tuning is performed, there are several important engineering considerations to ensure the adapted model is deployed correctly.




